Boosting Large Language Models (LLMs) applications with tools to interact with third-party services enables LLMs to retrieve updated knowledge and perform actions on behalf of users. However, the added capability brings security and privacy risks. In the current paradigm, users delegate potentially sensitive resources to LLM Apps, which makes the platforms overprivileged. For instance, malicious platforms or rogue models can exploit shared email-sending or TAP platform tokens stealthily. We propose LLMacaroon, a practical and secure architecture that distrusts applications for sharing sensitive resources and shifts control back to users. LLMacaroon achieves flexible, controlled sharing via macaroons and improves transparency and control via a local action proxy with optionally human in the loop. We demonstrate that LLMacaroon requires minimal changes to existing LLM apps and is compatible with major platforms like ChatGPT for various use cases.
1. Introduction
Instruction-following language models, such as GPT4 1, have achieved remarkable success in natural language understanding 2, commonsense reasoning 3, and open-domain QA 4 and continue to drive real world successes. Recent LLM applications have been deployed with planning 5, retrieval 6, and tool utilization 7 capabilities, allowing them to connect to external services and automate complex tasks. A notable example is ChatGPT, which provides users with a platform to interact with LLMs equipped with plugins and actions that encompass document retrieval, code execution, and communication with third-party services like Expedia and Zapier. Furthermore, there are a number of independently deployed applications that transform these models into agents capable of performing specific tasks such as web searching 8, education 9, and healthcare assistance 10. We refer to these LLM-integrated applications that allow LLMs to interact with external resources as LLM apps.
There are significant potential security risks when deploying and managing LLMs apps, including indirect prompt injection and insecure output handling, which allow attackers to lead LLMs to generate unexpected outputs, as summarized in OWASP’s list of top 10 vulnerabilities found in LLM apps 11. This work focuses on mitigating one specific risk in the list, excessive agency, a result of LLM app’s ability to interface with external services and perform actions in response to a prompt. Specifically, we tackle the problem where LLM in apps are granted with excessive permission and functionality, and hence over-privileged. In such scenarios, malicious app developers and platforms (e.g. OpenAI) may compromise users’ privacy and data security by abusing the delegated privileges (e.g. checking user’s personal emails), rogue and oblivious models may perform irreversible actions on the shared resources (e.g. creating public Github repos 12), and external attackers may try to access protected resources.
While LLM apps need privileges for real-world utility, we mitigate the risks of over-privilege in the current LLM app architecture by achieving controlled sharing with Macaroons (i.e., cookies with contextual caveats) and improving transparency and control via a local action proxy with (optionally) human in the loop. These designs enable an architecture that allows users to practically distrust LLM apps by avoiding token sharing, which mitigates excessive permission. Additionally, third-party services, together with LLM apps, can attenuate privilege on resources, thereby reducing excessive functionality.
This paper offers the following contributions:
- We develop a security and privacy-sensitive architecture for LLM apps, called LLMacaroon, that reduces the risk of over-privilege in LLM apps. LLMacaroon achieves controlled sharing of resources and improves transparency and control for users.
- We demonstrate that LLMacaroon can be practically deployed with acceptable changes to existing infrastructure using prototype LLM apps. We also show its applicability to both self-deployed LLM apps and centralized platforms like OpenAI GPTs.
2. Background
LLM application vulnerabilities.
Integrating API-interfacing ability into the LLM ecosystem exposes additional attack surfaces. Recent works have suggested that plugins introduce attack surfaces between plugins and users, plugins and LLM platform, and between plugins 13. These exposed attack surfaces allow potential malicious plugins to launch attacks targeting users, LLM platforms, and other plugins 14. Malicious plugins could potentially hijack users’ machines, hijack the LLM platform, and hijack other plugins 15.
LLM apps can also be compromised with Indirect Prompt Injection. An attacker could inject an adversarial prompt into sources that are likely to be retrieved by the LLM or third-party services 16. For example, if the LLM has web searching capabilities, then the attacker could place prompts on webpages, causing it to be controlled by attackers 17. This is usually hidden from users because the API calls are executed in the background on remote servers.
Access Control in LLM Apps.
Traditional token-based mechanisms are commonly used in LLM apps for permission delegation. Most commonly, this is done either via service-level authentication (e.g., fixed bearer token) to delegate access to the LLM app without linking specific users, or user-level authentication (e.g., OAuth) to delegate user-specific resources. We conducted a pilot study on ChatGPT Plugins. Developers on this platform use manifest files to define the behavior of their plugins. We analyzed the authentication methods used in 866 publicly available plugin manifests (Table 1). Our results show that 17.9% of plugins need user-level authentication for their functionality, and 13.74% conduct service-level authentication, which together constitute a considerable portion of all applications. This result may suggest the prevalence of the need for user-specific authentication in the growing LLM app ecosystem.
| Method | Count | Percentage |
|---|---|---|
| None | 592 | 68.36% |
| OAuth | 155 | 17.9% |
| Bearer | 155 | 13.28% |
| Basic | 4 | 0.46% |
Table 1: Authentication methods from collected 866 ChatGPT Plugin manifests
3. Design Goals and Threat Model
Our goal is to restrict the privilege of LLM apps so that malicious or oblivious LLM apps do not compromise user’s privacy and data security. Meanwhile, we want to impose minimal change to LLM app’s functionalities, where users can exercise controlled sharing for delegating specific resources. We first describe the threat model under which we design the system. Then we state the design goals for LLMacaroon. Finally, we present several alternative approaches which we did not implement since they fail to achieve our design goals.
3.1 Threat Model
To capture a stronger security notion, we assume the LLM app – both its components like the model itself and the app’s providers – might be untrustworthy. For instance, the LLM app might use a user’s shared token to stealthily inspect their personal documents, or perform malicious actions like deleting emails in response to a user’s normal prompt. This is a realistic assumption since LLM-integrated are shown to be unreliable under certain scenarios including indirect prompt injection 18, and LLM app platforms like ChatGPT, being overprivileged hubs of user tokens, are particularly susceptible to security breaches.
On the other hand, we trust end-users of the LLM app, who do not expect actions to their own detriment. Therefore, jail breaking 19 20 and general prompt injection attacks are out of scope of this work. However, we expect standard attackers of the system who want to access resources outside their permission (e.g. other users’ documents).
3.2 Design Goals
Security and Privacy.
Our primary goal is to reduce the long-lived privileges in LLM apps and only grant ephemeral access to necessary resources while the system is in use. This is to ensure that malicious LLMs and their providers do not abuse the privilege for extraneous purposes that threaten users’ privacy and data security. Our additional focus is to give users transparency and control so that they can exercise their discretion while interacting with the LLM apps. This is to provide more fine-grained control during the period when LLM apps have ephemeral privileges. Finally, the design should not open up new vulnerabilities for the standard security model of LLM apps and privileges of users should be well isolated.
Functionality.
The design to reduce long-lived privileges in LLM apps must not sacrifice the existing functionalities of LLM apps and their development flexibility. For instance, LLM apps should still be able to communicate to external services and perform the same set of actions spanning from knowledge retrieval to tool usage. Moreover, LLM apps should be able to implement user-specific business logics and attenuate privileges in a fine-grained manner for different users.
3.3 Alternative Designs
Offline LLM Apps.
Offline LLM apps provide the strongest privacy and security guarantees to the users if no data leaves the local execution environment (e.g. privateGPT 21. However, completely offline apps sacrifice usability and practical convenience for general users, and it may hinder the service provider’s flexibility to customize user experiences, which often requires granting different sets of privileges, violating the functionality design goal.
Application-end human in the loop.
Application platforms like ChatGPT provide an option to prompt for user confirmation before the LLM app performs consequential behaviors 22. This reduces the chance of accidental execution of unwanted actions. However, this mechanism does not offer security guarantee, especially when the application platform is untrusted. Hence, it is not sufficient for our security goal.
Privilege minimization.
Privilege minimization in LLM apps involves granting only essential access levels for functionality. Traditional methods often grant permissions without adequate context and fail to restrict access based on time, allowing unnecessary access to sensitive data even when not actively using the app. Therefore, we consider traditional privilege minimization insufficient, and advancements in this line of research should be orthogonal to our design. Our approach uses macaroon to contextually attenuate privileges, which offers better flexibility.
4. LLMacaroon Designs
To address the threat model and achieve the design goals outlined in Section 3, we propose LLMacaroon, a novel architecture that minimizes the risks of excessive agency in LLM apps and improves user transparency and control, thereby providing better security against threats from untrusted platforms and app providers when models are delegated to handle sensitive resources. LLMacaroon assumes typical LLM app setup where users interact with remotely hosted app that performs actions on behalf of the user by calling third-party destination services. We summarize the design and discuss the individual components in this section.
Design Overview.
Unlike the standard paradigm, where users delegate sensitive resources to a LLM app and the application performs actions autonomously, we make several paradigm shifts. These changes remove long-lived privileges from the LLM app while allowing them to conduct controlled sharing via contextual attenuation of actions.
- Rather than storing tokens with actual privileges, LLM apps only hold macaroons with partially fulfilled third-party caveats from destination services (4.1). This requires all actions to go through a local proxy, which gathers necessary discharges.
- The LLM app sends the intended action to a trusted local action proxy (4.2) for execution. The proxy gathers third-party authorization and user consent before forwarding actions to the destination service. The LLM app cannot perform actions when the proxy is offline, guaranteeing temporal access restriction.
- Both the LLM app and third-party services may additionally attenuate the privilege on macaroons by adding first-party caveats to confine the functionality of the actions. Destination services contextually verify all caveats before executing the incoming actions (4.3).

4.1 Macaroon Construction
LLMacaroon employs macaroons for controlled sharing of resources among principals in an LLM app system. The destination service delegates resources on its server for LLM apps to use by minting macaroons and adding first-party caveats that outline the access patterns, which often restrict user identity, resource URI, and time limit. The destination service must also add a third-party caveat to be fulfilled by discharges from authorization services. The service adds caveats using a chained-HMAC construction, whose integrity can be proved with the destination service’s secret key. The construction of a macaroon can be initiated by the LLM app at the start of a session, such that it holds the partially fulfilled macaroon during the session and attach it to a request to the user’s local proxy for an action execution.
Transmission.
After its construction, the macaron attaches to requests to be shared between services. Specifically, it can be serialized as a string and attached as an HTTP header value or as a cookie if the proxy implements methods for handling cookie semantics. The first hop after a macaroon’s construction is the LLM app, which may temporarily store the macaroon on a session basis or a request basis and attenuate it accordingly. The macaroon is forwarded to the proxy and then to the destination service when the LLM app initiates an action.
Application-Side Attenuation.
The LLM app can also attenuate the macaroon’s authority by adding first-party caveats, which is helpful for adding application-specific access control (e.g. a user only see documents with certain tags in a LLM document retrieval app). The attenuation may also prevent misuse of the authority by imposing narrower time and scope limit based on application specific requirements. The LLM app gains knowledge about the supported caveats by inspecting the destination service’s specification out-of-band.
4.2 Local Action Proxy
To perform an action and call a third-party service, the LLM app has to send the request to a trusted local action proxy. A direct call to the destination service will fail because of the unfulfilled third-party caveat. The proxy is responsible for obtaining authority from a third-party authorization service as well as users’ consent based on a user’s policy. The implementation of such proxy can take the form of a browser extension or a local service with web interface, but it carries the following features.
Authorization.
In LLMacaroon, the local action proxy replaces the LLM app’s responsibility for obtaining and storing authorizing tokens, thereby minimizing the privilege of LLM apps. On the LLM’s first request to the proxy for the delegation of an action, the user is prompted to authenticate with (third-party) authentication service, which returns a discharge to the proxy upon success. The discharge might contain first-party caveats (e.g. to ensure its freshness) and is bound to the main macaron (i.e. sealed) before being sent to the destination service. With the user’s consent, the proxy may store the discharge identified by request origins to a local database, analogous to browsers’ storage of authorization tokens. Subsequent requests to the local proxy may look up the discharge storage to prevent repetitive authentication.
Transparency and Control.
The proxy provides mechanisms that support transparency and user control in the interaction with LLM apps. This includes supporting users to decide individual action outcomes or specify policies for relaxed automation. Specifically, the proxy 1) presents a transparent log of actions requested by the LLM app as well as the proxy decisions, 2) allows users to customize their authorization preferences, including setting up rules for automatic approvals and specifying conditions under which manual approval is required, and 3) sends real-time notifications to the user in case immediate input is required and allows user to manually intervene and change the decision made by the proxy in real-time. These ensure the user has a transparent view of the proxy behavior and has governance over action requests.
4.3 Action Verification
If it is able to collect authorizing discharges and either automated or manual approval, the proxy forwards the request to the destination service with the main macaroon, as well as the collected third-party authenticating macaroons. Before processing the request, the destination service verifies all caveats attached to it. The service rejects the requests if the verification is unsuccessful.
Contextual Verification.
The destination service performs a contextual verification process, which involves assessing the validity of the macaroon in the context of the current request. This means checking not only the integrity and authenticity of the macaroon itself but also ensuring that the caveats are relevant and appropriate for the specific request being made. For instance, if a macaroon has a time limit caveat, the service checks the current time against this limit. Similarly, if there are resource-specific caveats, the service confirms that the request aligns with these constraints. This maintains a secure and context-aware authorization system.
4.4 Implementation
Services.
We provided a Python library for adding macaroon-based access control to services. The library allows services to integrate macaroon authorization with minimal changes by simply adding a middleware component and providing a set of validators for caveats. We leverage the existing pymacaroon library for macaroon construction and verification and integrate it with the FastAPI framework for building the services.
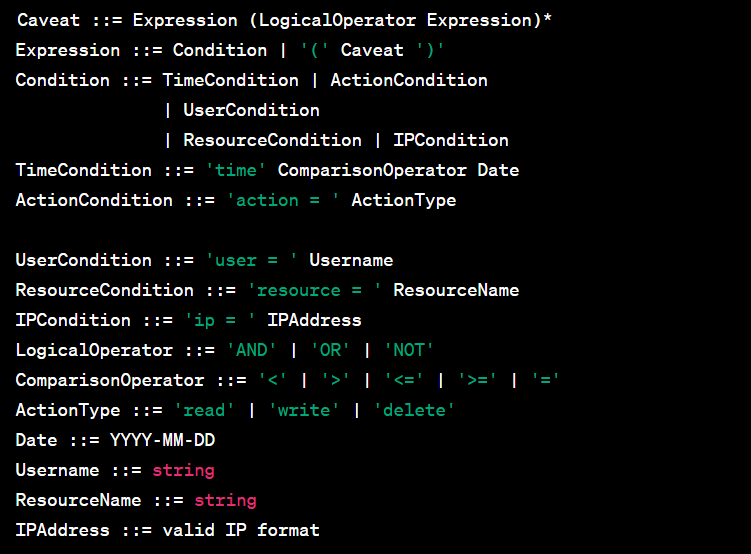
The library also includes a domain-specific language (DSL) for defining caveats and creating validators, supporting basic data types like strings, numbers, and dates as well as binary operators for constraints. The DSL enables services to flexibly specify caveats with placeholders that can be contextually verified at runtime so that developers do not need to repeat parsing and expression evaluation code. These toolings give both the flexibility and the convenience for services to control sharing. The formal definition of DSL is in Appendix A.
Proxy
We implemented a functional local action proxy server with features outlined in 4.2. It handles obtaining third-party discharges in exchange for user authentication and conditionally stores them in a local database indexed by requesting origins. The proxy server exposes a single endpoint for forwarding actions to destination services. If the request is not blocked by authentication, we stream the body to reduce latency.
The proxy runs a Svelte-based web interface that runs on a separate process that communicates actions and decisions with the server over a WebSocket. This front-end component allows users to view action logs, set authorization preferences, manually approve requests, and override automated decisions. Together, the proxy server and web interface deliver transparency and control.
LLM Apps.
For rapid prototyping of standard LLM apps, we leverage OpenAI’s platform, GPTs, which offers easy integration of actions. We wrap existing service endpoints as parameters to the proxy server’s forwarding endpoint. The LLM apps access allowed actions and services but delegate execution to the local proxy.
Macaroons are supplied to LLM apps as static authorization tokens configured through OpenAI’s interface. We attach them via a custom “x-macaroon” header that services recognize for verification. The macaroons contain pre-defined caveats equivalent to the ones programmatically added by self-hosted LLM app implementations.
4.5 Examples
We implemented several LLM apps that builds upon the LLMacaroon architecture.
Manipulating sensitive resources (Email Assistant).
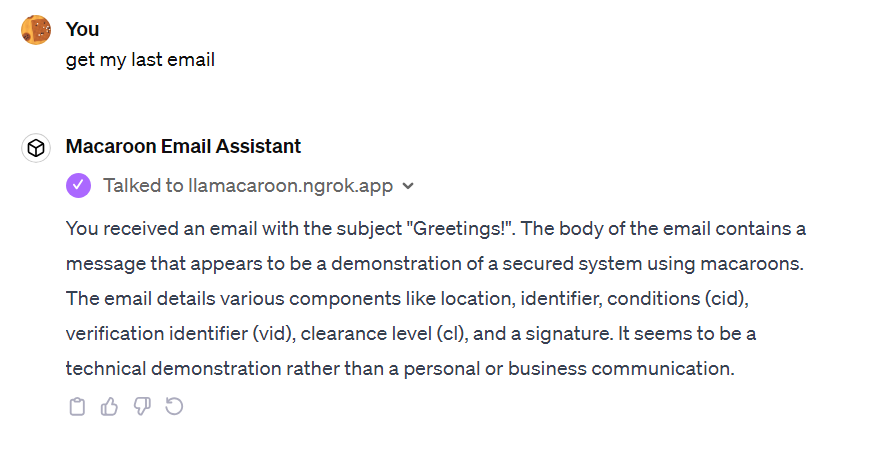
We created a GPT plug-in called GPT email service using OpenAI’s plug-in building tool. The app reads and sends emails on behalf of the user. This app requires reading users’ sensitive data (emails) and performing irreversible actions such as sending emails. We also created each of our design components described in 4: a proxy, an authentication service, and a simple email service. We assume the LLM email app has already obtained the undischarged Macaroon from the simple email service. This macaroon is then passed along as a custom API key. We then prompted the GPT email app to get the user’s last email. The app requests our proxy service with the undischarged macaroon. The proxy receives the macaroon, obtains the discharge from the third-party service, and sends it to the simple email service. The email service verifies the signature, all the caveats, and all the discharges. After they are verified, the email service calls the read method and sends the result of read - which is the user’s latest email - back to the proxy. The proxy then sends the response back to the GPT email app. Finally, the GPT email app is able to obtain the user’s latest email and successfully outputs the subject and content information to ChatGPT’s UI.
Retrieval Augmented Generation with Shared Data (Documents Search).
Another common class of applications delegates documents to the LLM for retrieval, so that the LLM app conducts generation with grounded, up-to-date knowledge. We implemented an LLM app with RAG ability using the LLMacaroon design. The LLM is given an API to query relevant data from a third-party service that owns a Pinecone vector database and performs embedding similarity search with LangChain. We then protect the API by using Macaroon for authentication and controlled sharing. Specifically, the service may allow access to only a part of the database by adding caveats that check document labels. This also enables cooperative LLM apps to refine the authority given to users (e.g., with a time limit), but malicious apps cannot amplify the authority.
Remote Code execution (Python Interpreter).
Finally, we implemented an example LLM app that can execute Python code on users’ delegated personal computing environment on a prototype service (similar to ECS). We note that fully allowing an LLM app to execute code on a personal computing environment is risky, even when the environment is sandboxed. For example, a malicious LLM app might attack the availability of the computing resource by overloading it. With LLMacaroon, we improved the prototype LLM app by allowing it to request the execution of Python snippets on a third-party service, where the user owns a Docker container. The request goes through the action proxy, and the user may inspect the code before execution.
5. Evaluation
5.1 Functional Evaluation
Extensive tests are done on the prototype apps to ensure their functionality and correctness. In this section, we detail our functional evaluation on the email assistant app. We first prompted the GPT email app to read the user’s latest email by sending a request with the Macaroon given by our email service to our architecture. The request shows that GPT email app successfully obtained the user’s latest email.
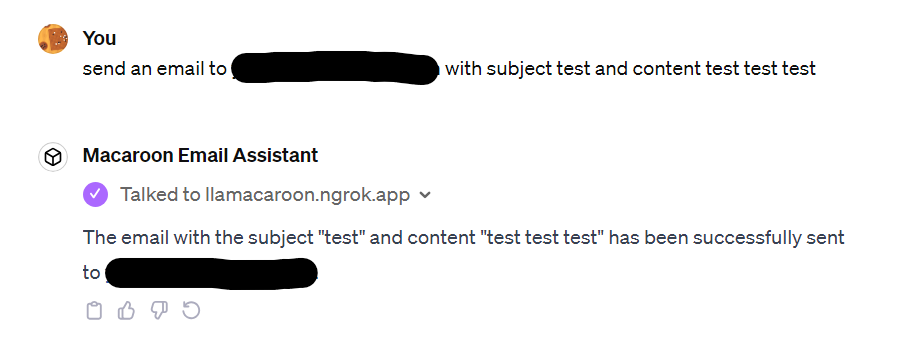
We also prompted the GPT email app to send an email using our architecture. Sending an email goes through the same process as reading the latest email, except that it calls the email service’ send function instead of the read function. Although the context is different, we didn’t need to write a new validator because our DSL described in 4.4 is able to contextually verify the caveats. The end result is that the GPT email app is able to email one of the researcher’s mailbox. The full interaction is in Appendix B.
We then shut down the third-party authentication service and prompted the GPT email app to read the user’s last email. This is to simulate a direct API call from the GPT email app to the email service. The email service is unable to verify the discharges and returns an error. The result is that the GPT email app is unable to get the user’s latest email.
GPT email app’s inability to directly perform email actions demonstrates the principle of least privilege. The privilege to perform critical email actions is now returned to the user.
5.2 Performance Evaluation
The performance overhead of Macaroon operations has already been discussed by Birgisson et al. 23. To test the performance overhead for our architecture, we conduct an end-to-end application performance test on a no-op prototype apps.
We measure the total time it took for each operation with respect to the number of caveats attenuated. We measured the proxy overhead, discharge overhead, macaroon verification overhead, and overall architecture overhead. The proxy overhead includes the discharge overhead. Proxy overhead is measured by starting a timer when the request is received and stopping the timer when the request is about to be routed to the email service server. We obtained the overall architecture overhead by taking the sum of proxy overhead and macaroon validation overhead. This is because the overhead of routing and sending HTTP requests to the email service server is also done even without using our architecture. Therefore, the routing of HTTP requests is not included. Figure 2 shows our performance evaluation of the GPT email app.
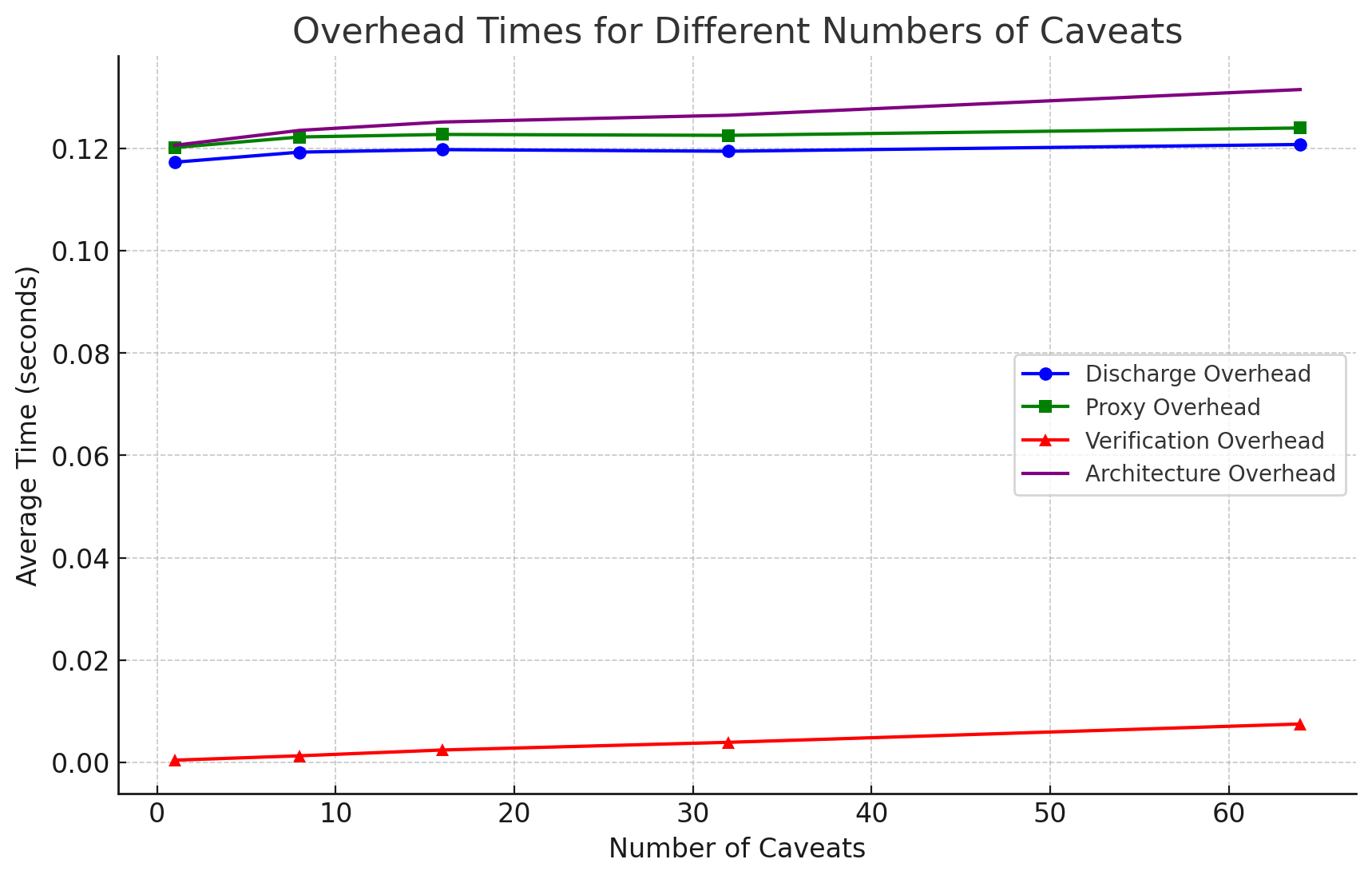
In Figure 2, we present a graph of comprehensive analysis of performance. The y-axis represents the average time measured in seconds, and the x-axis denotes the number of caveats in a macaroon. The data depicted in this graph indicates an almost constant architecture overhead of 0.13 seconds. The main contributor to this overhead is the routing of macaroon to the third-party discharge service. The discharge overhead contributed to 95.15% of the overall architecture overhead. We foresee that most GPT plugins would typically utilize only a few caveats. Consequently, the security enhancements provided by LLMacaroon are achieved with a minimal impact on performance, as demonstrated by the overhead figures for a modest number of caveats.
6. Discussion and Limitation
This paper introduces a novel architecture, LLMacaroon, designed to enhance the security and privacy of Large Language Model (LLM) applications. LLMacaroon employs macaroons for controlled sharing of resources and incorporates a local action proxy to increase user transparency and control. However, we note some limitations that can be studied in future works.
Usability
The introduction of the local action proxy is a step towards handing back transparency and control to users, which opens up opportunities for more effective user-centric designs. This proxy can be implemented in various forms, such as a browser extension or a local web application, allowing users to exercise more direct control over their interactions with LLM applications.
However, the effectiveness of these implementations in real-world scenarios remains unexplored, as our current work does not focus on interaction design. Future work should investigate the impact of different proxy implementations on user experience and the effectiveness of user control in practical settings, possibly through intelligent, context-aware interfaces that reduce the cognitive load on users. Additionally, exploring decentralized approaches for the action proxy could further enhance trust and security in the system, as we shift trust from LLM apps to the proxy.
Adoption
For LLM applications, adoption of LLMacaroon does not necessitate major changes, preserving their existing functionality. However, services interfacing with these applications need modifications to adhere to the additional security constraints introduced by LLMacaroon. From the user’s perspective, installing an action proxy can be optional, allowing users to opt for the existing paradigm if they choose. This flexibility supports a gradual transition to the new architecture, reducing barriers to adoption. Future studies should explore the user acceptance and adoption rates of the action proxy, examining factors that influence users’ decisions to adopt or reject this new layer of control and security.
Broader Implications
LLMacaroon may extend beyond LLM applications, potentially influencing the design of other types of applications that handle sensitive user data or require controlled resource sharing. The concepts introduced in this architecture could inspire new approaches to user-centric privacy and security across various domains.
Acknowledgements
We want to thank Professor Earlence Fernandes and TA Alisha Ukani for many helpful discussions.
Appendix
A. Formal Definition
B. GPT Email APP Interaction
C. Proxy Interface
Here are the references converted into footnotes using Markdown syntax:
OpenAI. “GPT-4 Technical Report,” March 27, 2023. http://arxiv.org/abs/2303.08774.↩︎
Wolf, Thomas, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pierric Cistac, et al. “Transformers: State-of-the-Art Natural Language Processing.” In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, 38–45. Online: Association for Computational Linguistics, 2020. https://aclanthology.org/2020.emnlp-demos.6.↩︎
Talmor, Alon, Jonathan Herzig, Nicholas Lourie, and Jonathan Berant. “CommonsenseQA: A Question Answering Challenge Targeting Commonsense Knowledge,” March 15, 2019. http://arxiv.org/abs/1811.00937.↩︎
Dunn, Matthew, Levent Sagun, Mike Higgins, V. Ugur Guney, Volkan Cirik, and Kyunghyun Cho. “SearchQA: A New Q&A Dataset Augmented with Context from a Search Engine,” June 11, 2017. http://arxiv.org/abs/1704.05179.↩︎
Yao, Shunyu, Dian Yu, Jeffrey Zhao, Izhak Shafran, Thomas L. Griffiths, Yuan Cao, and Karthik Narasimhan. “Tree of Thoughts: Deliberate Problem Solving with Large Language Models,” December 3, 2023. http://arxiv.org/abs/2305.10601.↩︎
Lewis, Patrick, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, et al. “Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks.” In Advances in Neural Information Processing Systems, 33:9459–74. Curran Associates, Inc., 2020. https://proceedings.neurips.cc/paper/2020/hash/6b493230205f780e1bc26945df7481e5-Abstract.html.↩︎
Schick, Timo, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. “Toolformer: Language Models Can Teach Themselves to Use Tools,” February 9, 2023. http://arxiv.org/abs/2302.04761.↩︎
“Bing Chat | Microsoft Edge.” Accessed December 11, 2023. https://www.microsoft.com/en-us/edge/features/bing-chat.↩︎
“Introducing Duolingo Max, a learning experience powered by GPT-4.” Duolingo Blog, March 14, 2023. https://blog.duolingo.com/duolingo-max/.↩︎
Clusmann, Jan, Fiona R. Kolbinger, Hannah Sophie Muti, Zunamys I. Carrero, Jan-Niklas Eckardt, Narmin Ghaffari Laleh, Chiara Maria Lavinia Löffler, et al. “The Future Landscape of Large Language Models in Medicine.” Communications Medicine 3, no. 1 (October 10, 2023): 1–8. https://doi.org/10.1038/s43856-023-00370-1.↩︎
Wilson, Steve, and others. “OWASP Top 10 for Large Language Models (LLMs) - 2023,” 2023. https://owasp.org/www-project-top-10-for-large-language-model-applications.↩︎
Iqbal, Umar, Tadayoshi Kohno, and Franziska Roesner. “LLM Platform Security: Applying a Systematic Evaluation Framework to OpenAI’s ChatGPT Plugins.” 2023. https://llm-platform-security.github.io/chatgpt-plugin-eval.↩︎
Iqbal, Umar, Tadayoshi Kohno, and Franziska Roesner. “LLM Platform Security: Applying a Systematic Evaluation Framework to OpenAI’s ChatGPT Plugins.” 2023. https://llm-platform-security.github.io/chatgpt-plugin-eval.↩︎
Iqbal, Umar, Tadayoshi Kohno, and Franziska Roesner. “LLM Platform Security: Applying a Systematic Evaluation Framework to OpenAI’s ChatGPT Plugins.” 2023. https://llm-platform-security.github.io/chatgpt-plugin-eval.↩︎
Greshake, Kai, Sahar Abdelnabi, Shailesh Mishra, Christoph Endres, and Thorsten Holz. “Not what you’ve signed up for: Compromising Real-World LLM-Integrated Applications with Indirect Prompt Injection.” Unknown Journal, 2023. Saarland University, Sequire Technology GmbH, CISPA Helmholtz Center for Information Security.↩︎
Greshake, Kai, Sahar Abdelnabi, Shailesh Mishra, Christoph Endres, and Thorsten Holz. “Not what you’ve signed up for: Compromising Real-World LLM-Integrated Applications with Indirect Prompt Injection.” Unknown Journal, 2023. Saarland University, Sequire Technology GmbH, CISPA Helmholtz Center for Information Security.↩︎
Greshake, Kai, Sahar Abdelnabi, Shailesh Mishra, Christoph Endres, Thorsten Holz, and Mario Fritz. “Not What You’ve Signed up For: Compromising Real-World LLM-Integrated Applications with Indirect Prompt Injection,” 2023.↩︎
Wei, Alexander, Nika Haghtalab, and Jacob Steinhardt. “Jailbroken: How Does LLM Safety Training Fail?,” 2023.↩︎
Zou, Andy, Zifan Wang, J. Zico Kolter, and Matt Fredrikson. “Universal and Transferable Adversarial Attacks on Aligned Language Models,” 2023.↩︎
Martínez Toro, Iván, Daniel Gallego Vico, and Pablo Orgaz. “PrivateGPT.” May 2023. https://github.com/imartinez/privateGPT.↩︎
OpenAI. “Actions in GPTs.” https://platform.openai.com/docs/actions.↩︎
Birgisson, Arnar, Joe Gibbs Politz, Úlfar Erlingsson, Ankur Taly, Michael Vrable, and Mark Lentczner. “Macaroons: Cookies with Contextual Caveats for Decentralized Authorization in the Cloud,” 2013.↩︎